如果有看我之前文章的朋友會知道,我對於 Docker 實戰六堂課 這本書讚譽有加,因為它不僅理論基礎紮實,還提供了非常實用的實作範例,幫助讀者快速掌握 Docker 和 Linux 的核心概念與應用。受到啟發,我寫了 從 Linux 基礎實現 Docker Bridge 網路:一步步理解容器通訊 (1) 系列文章。
上週小賴老師舉辦了一場直播,探討該書中未提及的容器資源限制,並進行了相關實驗。內容依然簡潔、精彩且實用。因此,我打算以該直播內容為基礎,撰寫我的理解、延伸內容與實作過程。
如果懶得閱讀文字,可以直接觀看小賴老師的直播回放 - 探索容器資源限制
Namespaces - Linux 的系統資源隔離
命名空間(Namespaces)是 Linux 核心提供的一種機制,用於隔離不同進程之間的全局系統資源。Docker 利用以下幾種命名空間來實現容器的隔離:
- PID 命名空間:隔離進程 ID,容器內的進程無法看到容器外的進程。
- NET 命名空間:隔離網路介面、IP 位址、路由表等,使每個容器擁有獨立的網路堆疊。
- MOUNT 命名空間:隔離檔案系統的掛載點,容器可以有自己的檔案系統視圖。
- IPC 命名空間:隔離進程間通信資源,如信號量和共享記憶體。
- UTS 命名空間:隔離主機名和域名,容器可以設定自己的主機名。
- USER 命名空間:隔離使用者和群組 ID,增強安全性。
簡單來說,Namespace 就像團體分組,各組(Namespace)彼此隔離,無法互相看到。Namespace 可以嵌套,類似層級分明的組織圖。不過,PID 命名空間比較特殊,因為它可以看到自己底下的子命名空間,而其他類型則無法。
透過這些命名空間,Docker 得以確保容器在進程、網路、檔案系統等方面的隔離,防止容器之間的相互干擾。目前只需要了解 Docker 和 Kubernetes 的 Namespace 都是基於這個機制來實現的。未來有機會會單獨寫一篇文章深入探討。詳情可參考 namespaces(7) — Linux manual page。
網路方面的 Namespace 實作,可參考系列文章:從 Linux 基礎實現 Docker Bridge 網路:一步步理解容器通訊 (1)。
cgroups - Linux 的計算資源限制
控制群組(cgroups)是 Linux 核心提供的另一種機制,用於限制、監控和隔離進程群組對計算資源的使用。Docker 利用 cgroups 來限制容器的資源消耗,包括:
- CPU 限制:限制容器可使用的 CPU 時間或核心數量。
- 記憶體限制:設定容器可使用的最大記憶體,包括物理記憶體和交換空間。
- 塊設備 I/O 限制:限制容器對磁碟的讀寫速率。
- 網路頻寬限制:限制容器的網路吞吐量。
透過配置 cgroups,Docker 能防止單個容器過度消耗系統資源,確保系統的穩定性與公平性。
cgroups 版本的差異
自 cgroups 引入以來,已經發展出兩個主要版本:cgroups v1 和 cgroups v2。cgroups v2 針對 v1 的複雜性和一致性問題進行了重大改進,主要透過統一層級結構和標準化介面。雖然需要一定的遷移工作,但 v2 提供更強大的功能、更一致的行為和更簡化的管理方式,有助於提升系統資源管理的效率與可靠性。
目前一些主流的 Linux 發行版,已經陸續預設啟用 cgroup v2,例如:
- Fedora (since 31)
- Arch Linux (since April 2021)
- openSUSE Tumbleweed (since c. 2021)
- Debian GNU/Linux (since 11)
- Ubuntu (since 21.10)
- RHEL 和 RHEL-like 發行版 (since 9)
要查看 Linux 使用的 cgroups 版本,可以使用以下指令:
1stat -fc %T /sys/fs/cgroup/cgroup v2 的輸出為 cgroup2fs;cgroup v1 的輸出為 tmpfs。
更多資訊可參考:Kubernetes - About cgroup v2。
以下是補充、修正與延伸後的版本,保持內容通順、精簡且正確:
CPU 和 Memory 資源的特性
要了解 CPU 的運作方式,我們需要引入作業系統的資源分配與調度概念,特別是 CPU 的時間分配與權重調整機制。而 Memory 資源則相對直觀,但其容量限制與管理機制也需要作業系統進行控制。
CPU
特性與運作
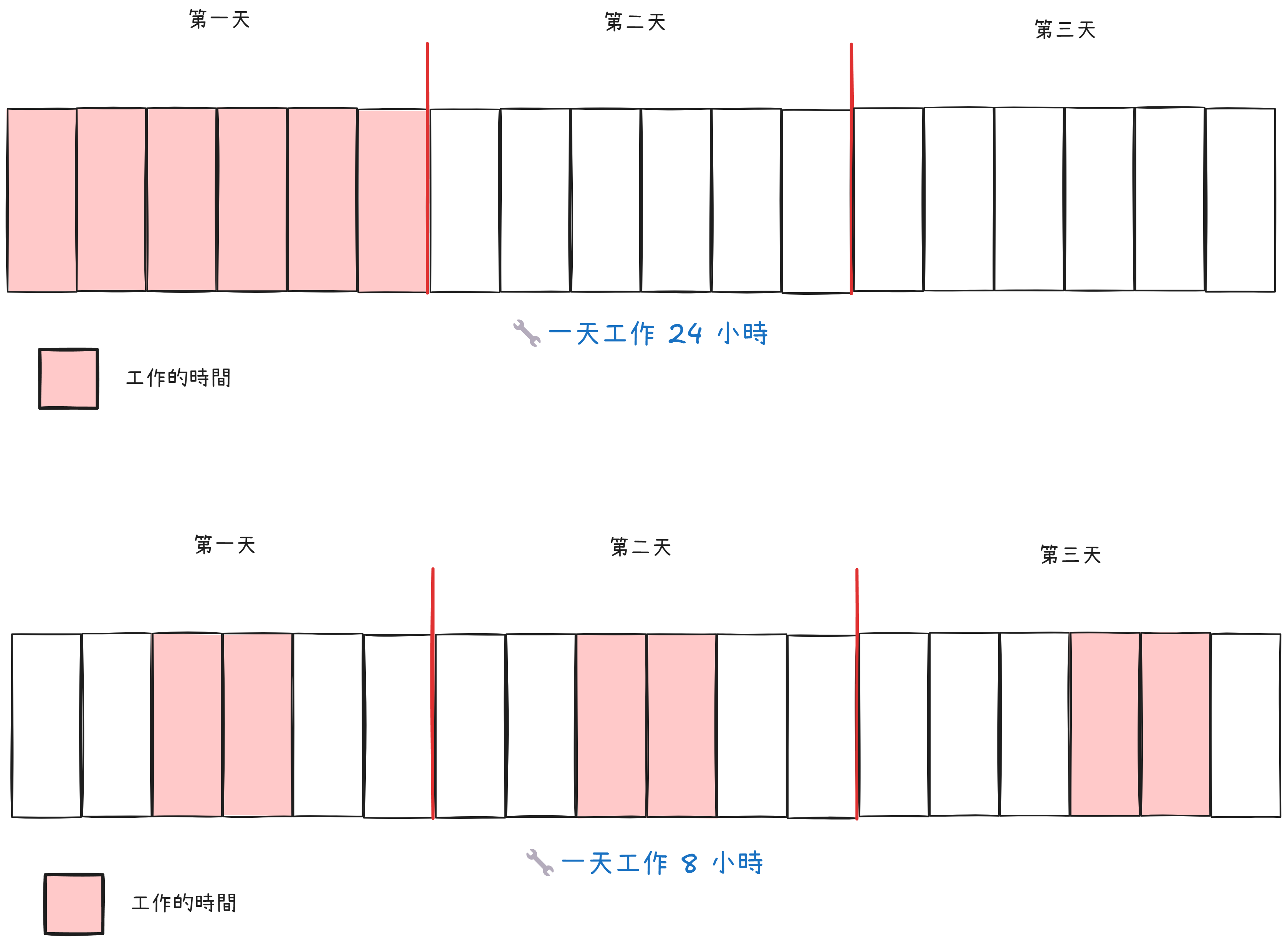
- 現代 Linux 系統預設使用 CFS(Completely Fair Scheduler) 來調度 CPU 時間,保證進程獲得「公平」的執行機會。
- CFS 將 CPU 核心視為工人,每個任務按權重分配工作時間。權重高的任務獲得更多資源,而權重低的任務仍有機會執行。
- 比喻:
- 工人每天有固定的工作時間,若專注於單一任務(權重高),可快速完成工作。
- 若多任務同時進行,工人將根據任務的重要性(權重)分配時間,每個任務都會被處理,但完成速度取決於其權重比例。

CPU 調度
- CFS 將 CPU 時間劃分為週期(如 100,000 微秒),進程按權重分配這段時間:
- 進程 A:權重為 1024,獲得 50% CPU 時間。
- 進程 B 和 C:權重各為 512,各獲得 25% CPU 時間。
- 當進程的 CPU 時間用盡,需等待下一週期分配資源。
- 優勢:
- 任務只會變慢,不會因資源不足而被終止,CPU 調度具有彈性(軟性限制)。
簡而言之
- CPU 調度機制確保所有進程能公平共享資源,根據權重比例分配時間,避免任務餓死。
- 即使資源緊張,低優先級任務也可在後續週期繼續執行。
Memory
特性與運作
- Memory 是用於暫存程式與資料的有限資源,可比喻為 出租倉庫:
- 倉庫空間有限,每個顧客(進程)需租用空間存放物品(資料)。
- 當倉庫已滿,新顧客需等現有顧客清理空間或離開,才能獲得存放空間。
記憶體管理
- 作業系統可透過
memory.limit_in_bytes或memory.max設定記憶體上限:- 當進程超出限制時,可能觸發 OOM(Out of Memory)Killer,強制終止記憶體超量使用的進程。
- 系統可能釋放部分緩存或非關鍵資源,但若空間不足,仍需終止某些進程以恢復穩定。
簡而言之
- Memory 限制是剛性的(硬性限制),進程無法超出上限使用記憶體。
- 當記憶體不足時,作業系統無法像 CPU 調度那樣「延後執行」,需直接終止部分進程以騰出資源。
表格對比
用表格簡單比對:
| 屬性 | CPU | Memory |
|---|---|---|
| 資源特性 | 彈性資源,可共享 | 固定資源,不可超量使用 |
| 限制機制 | 調度和優先級 | 硬性上限,觸發限制可能導致進程終止 |
| 不足時的行為 | 進程速度變慢,但可繼續執行 | 超量分配會導致應用崩潰或觸發 OOM Killer |
| 限制工具 | - cpu.max- cpu.shares | - memory.limit_in_bytes- memory.max |
| 適用場景 | 確保公平分配,防止 CPU 過載 | 防止記憶體洩漏,確保系統穩定性 |
實驗:使用 cgroups 限制進程 CPU 資源
實驗環境如下:
- Windows host: Windows 11 Pro 23H2
- WSL Version: 2.3.26.0
- WSL Distribution: Ubuntu 22.04.5 LTS
設置 cgroups v2
雖然我的 WSL 使用的是 Ubuntu 22.04 發行版,但預設卻是 cgroup v1:
1stat -fc %T /sys/fs/cgroup/2#3tmpfs這點在 KinD 的 Issues 中有提到。在 wsl-cgroupsv2 專案的說明文件中提到,WSL 2 默認運行在一種混合模式下,支持 cgroup v1 和 v2。這可能會導致在使用某些容器技術(如 Docker 或 Kubernetes)時出現問題。
自 Linux v5.0 起,Linux kernel boot option cgroup_no_v1=<list_of_controllers_to_disable> 可用於停用 cgroup v1 層級架構。根據 WSL 文件,我們必須在 %UserProfile%\.wslconfig 檔案中新增:
1[wsl2]2kernelCommandLine = cgroup_no_v1=all儲存後,使用以下指令重啟 WSL:
1wsl --shutdown2wsl -d Ubuntu-22.04再次查詢 cgroup 使用版本:
1stat -fc %T /sys/fs/cgroup/2#3cgroup2fs查看 cgroup 的位置
切換到 root 使用者,來到 /sys/fs/cgroup 資料夾,查看內容:
1$ sudo su2#3root@vince987:/#cd /sys/fs/cgroup4#5root@vince987:/sys/fs/cgroup# ls6#7cgroup.controllers cgroup.threads init.scope sys-kernel-debug.mount8cgroup.max.depth cpu.stat io.stat sys-kernel-tracing.mount9cgroup.max.descendants cpuset.cpus.effective memory.reclaim system.slice10cgroup.procs cpuset.mems.effective memory.stat user.slice11cgroup.stat dev-hugepages.mount misc.capacity12cgroup.subtree_control dev-mqueue.mount sys-fs-fuse-connections.mount從檔名可以看出,它可以定義諸如 cpu、memory、io 等計算資源。
我們在這個目錄下建立新資料夾 test_group,等於建立一個新的 group 來控制資源:
1root@vince987:/sys/fs/cgroup# mkdir test_group2#3root@vince987:/sys/fs/cgroup# cd test_group/4#5root@vince987:/sys/fs/cgroup/test_group# ls6cgroup.controllers cpu.stat hugetlb.2MB.current memory.oom.group7cgroup.events cpu.weight hugetlb.2MB.events memory.reclaim8cgroup.freeze cpu.weight.nice hugetlb.2MB.events.local memory.stat9cgroup.kill cpuset.cpus hugetlb.2MB.max memory.swap.current10cgroup.max.depth cpuset.cpus.effective hugetlb.2MB.rsvd.current memory.swap.events11cgroup.max.descendants cpuset.cpus.partition hugetlb.2MB.rsvd.max memory.swap.high12cgroup.procs cpuset.mems io.stat memory.swap.max13cgroup.stat cpuset.mems.effective memory.current misc.current14cgroup.subtree_control hugetlb.1GB.current memory.events misc.max15cgroup.threads hugetlb.1GB.events memory.events.local pids.current4 collapsed lines
16cgroup.type hugetlb.1GB.events.local memory.high pids.events17cpu.idle hugetlb.1GB.max memory.low pids.max18cpu.max hugetlb.1GB.rsvd.current memory.max rdma.current19cpu.max.burst hugetlb.1GB.rsvd.max memory.min rdma.max僅僅是在這建立資料夾,cgroup 就會自動幫我們做初始化。
打印 cpu.max 內容:
1cat cpu.max2#3max 100000這表示一個 CPU 週期是 100,000 微秒,而該 group 可以無限制地使用。
將 max 設定為 10,000,表示在 100,000 微秒的週期內,最多允許使用 10,000 微秒的 CPU 時間,即 10% 的 CPU 使用率:
1root@vince987:/sys/fs/cgroup/test_group# echo "10000 100000" | tee cpu.max2#310000 100000實驗步驟:
- 在終端 1,使用
htop工具監控資源使用情況。 - 在終端 2,使用 bash 執行無窮迴圈(
while : ; do : ; done),這會造成一顆 CPU 核心被用滿。 - 在終端 3,將 pid 寫入
cgroup.procs文件內,讓進程受到test_group控制。
結果如下:
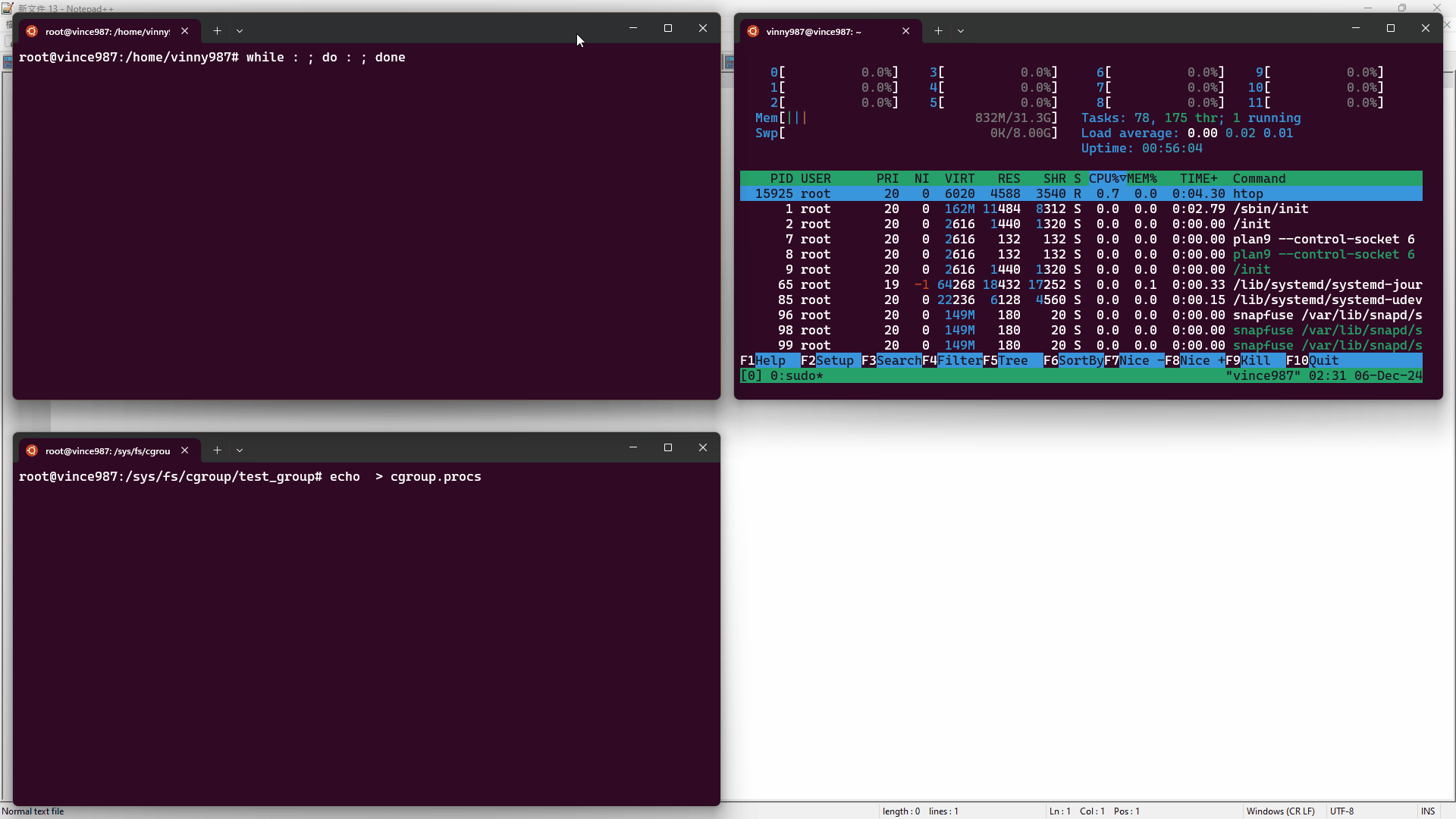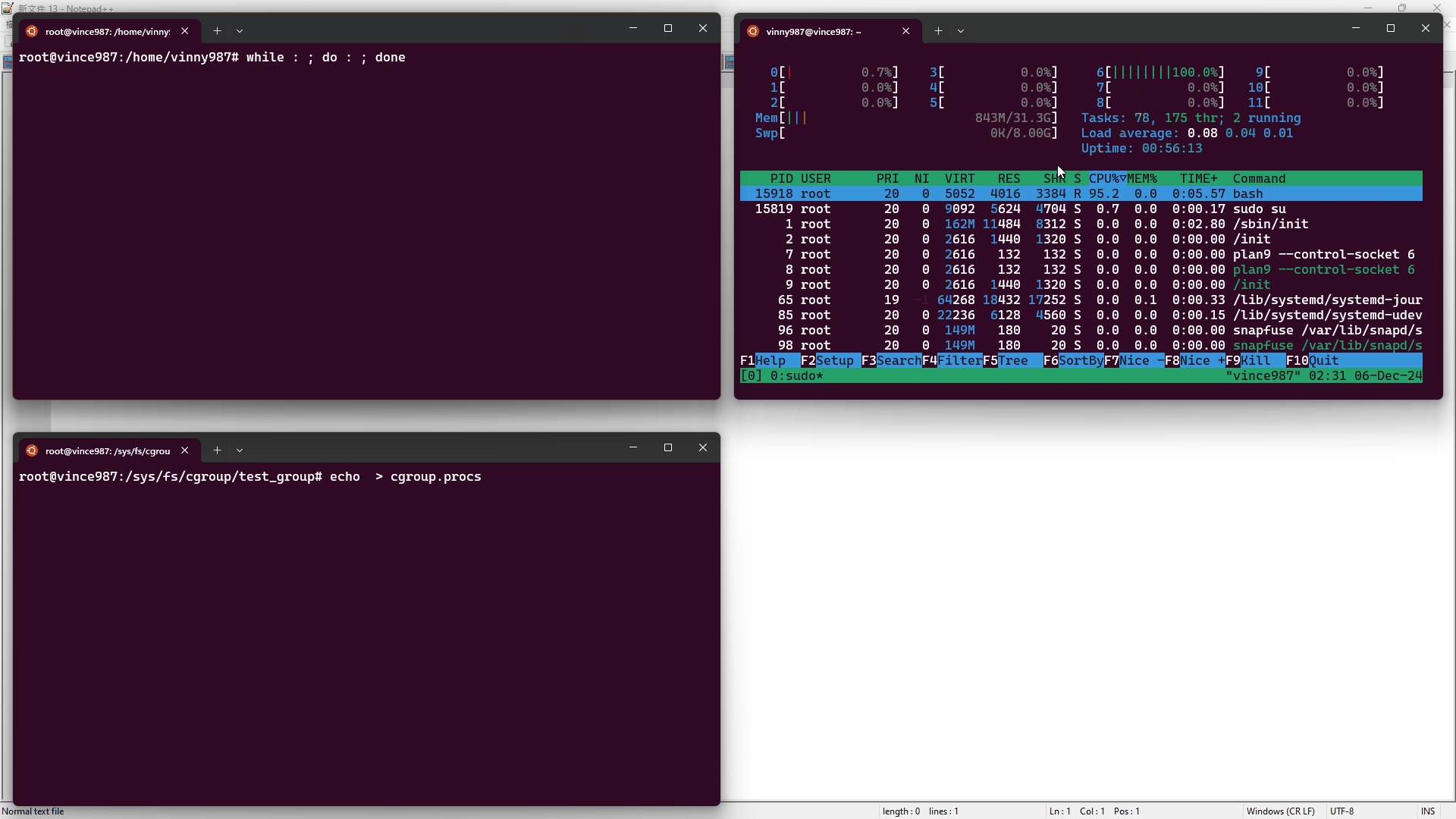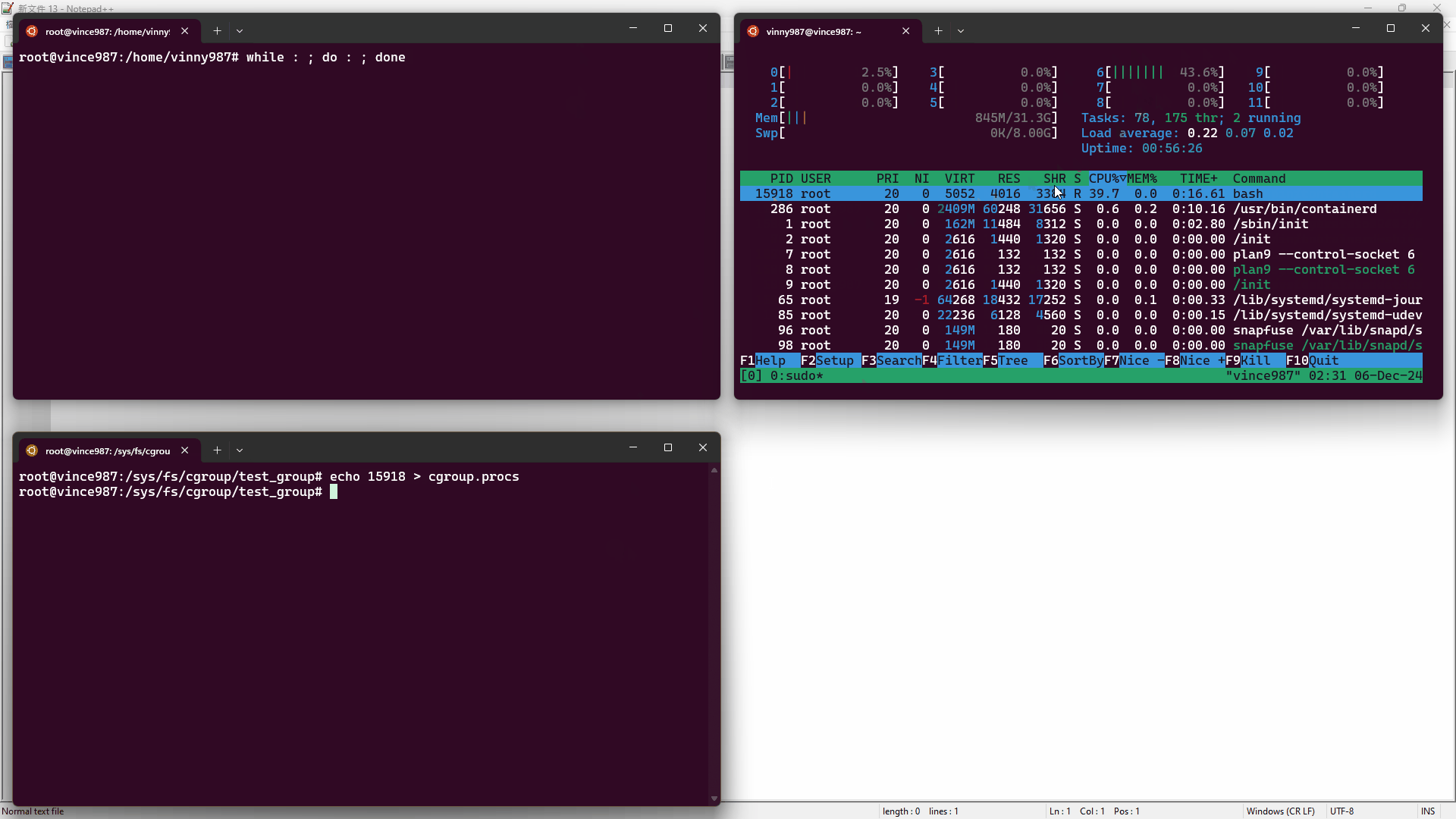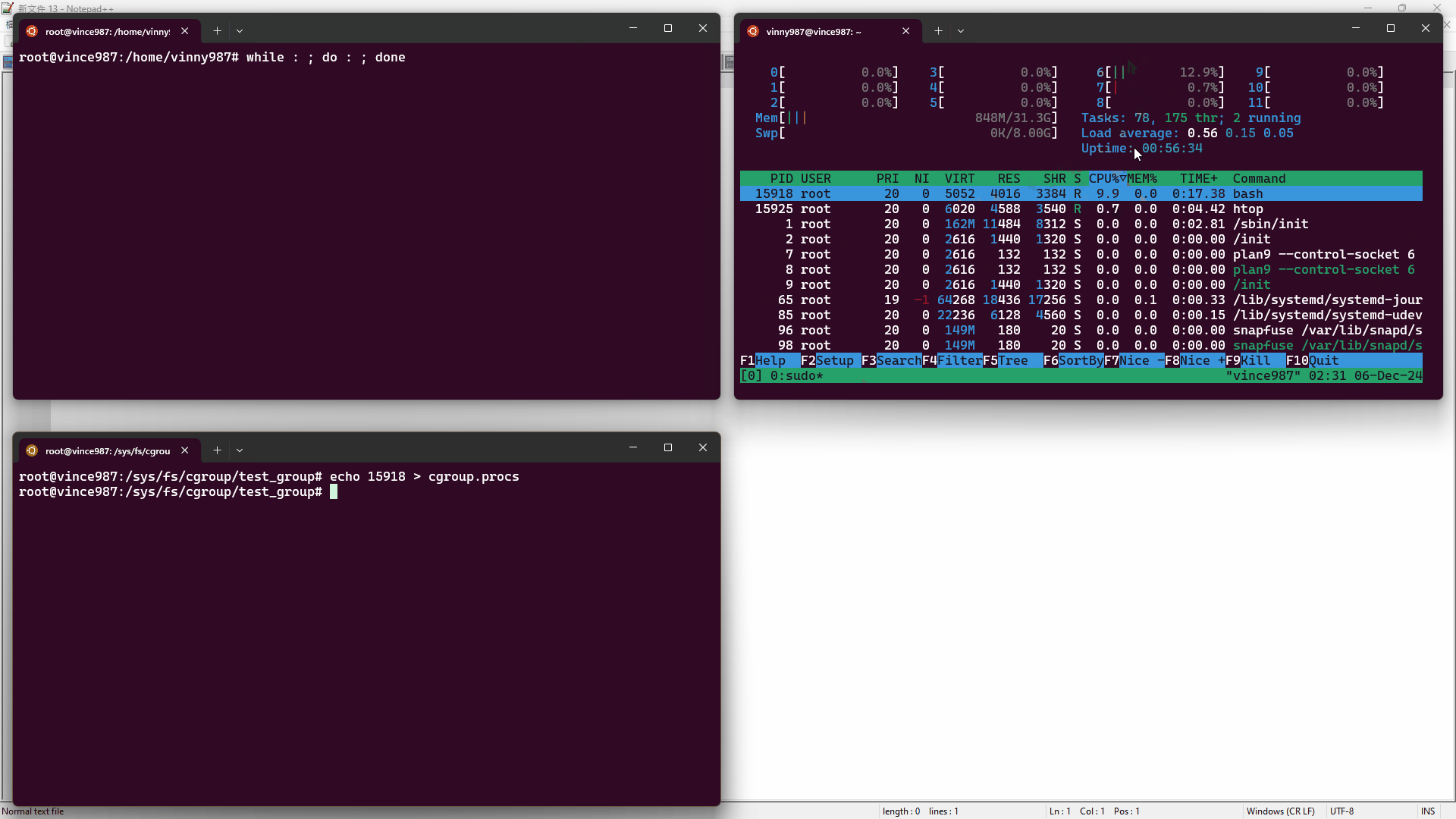
清理
在刪除 cgroup 時,必須確保其中沒有任何進程或子 cgroup,否則刪除操作會失敗。
1# 檢查是否有進程2cat /sys/fs/cgroup/test_group/cgroup.procs3
4# 如果有進程,移動進程到父 cgroup5for pid in $(cat /sys/fs/cgroup/test_group/cgroup.procs); do6 echo $pid > /sys/fs/cgroup/cgroup.procs7done8
9# 刪除 cgroup10cd /sys/fs/cgroup/11rmdir /sys/fs/cgroup/test_group建議使用現成工具(如 cgdelete)來移除 cgroup,等效於上述操作:
1# 安裝工具2sudo apt install cgroup-tools3
4# 移除5sudo cgdelete -g cpu:/test_groupMemory 的限制也是差不多的做法,就不另外展示。
小結
Linux 系統中,Namespaces 提供了進程、網路和檔案系統等多層面的隔離能力,使每個容器都像一個獨立的操作環境。cgroups 則在資源分配和限制上發揮了關鍵作用,避免單一容器過度消耗系統資源。
在實驗中,我們實現了使用 cgroups v2 來限制進程的 CPU 資源,並成功觀察到其效果,驗證了理論與實踐的一致性。
後續還有透過 Docker,來實踐和驗證資源分配和限制的特性,由於篇幅關係,就留到下一個章節繼續。